Why Most AI Search Content Fails Before It Starts

Author:
Ashley Peña
March 17, 2026
There are two ways to match a product to a high-intent AI search prompt. One starts from thin, surface-level data, a product title, a short description, maybe a few keywords. The other starts from the full product catalog: real SKUs, real engagement data, real attributes, real customer behavior. Same underlying technology. Completely different inputs. Completely different outputs.
Most AI search content is built on the first approach. That's why most of it fails.
When a user asks ChatGPT or Perplexity "what's the best supplement for muscle recovery after strength training," the AI is doing something specific: it's retrieving content that answers that question accurately, then surfacing the source it trusts most. What it's not doing is rewarding the brand that published the most content, or the one that used the most keywords. It's rewarding the brand whose content is actually right.
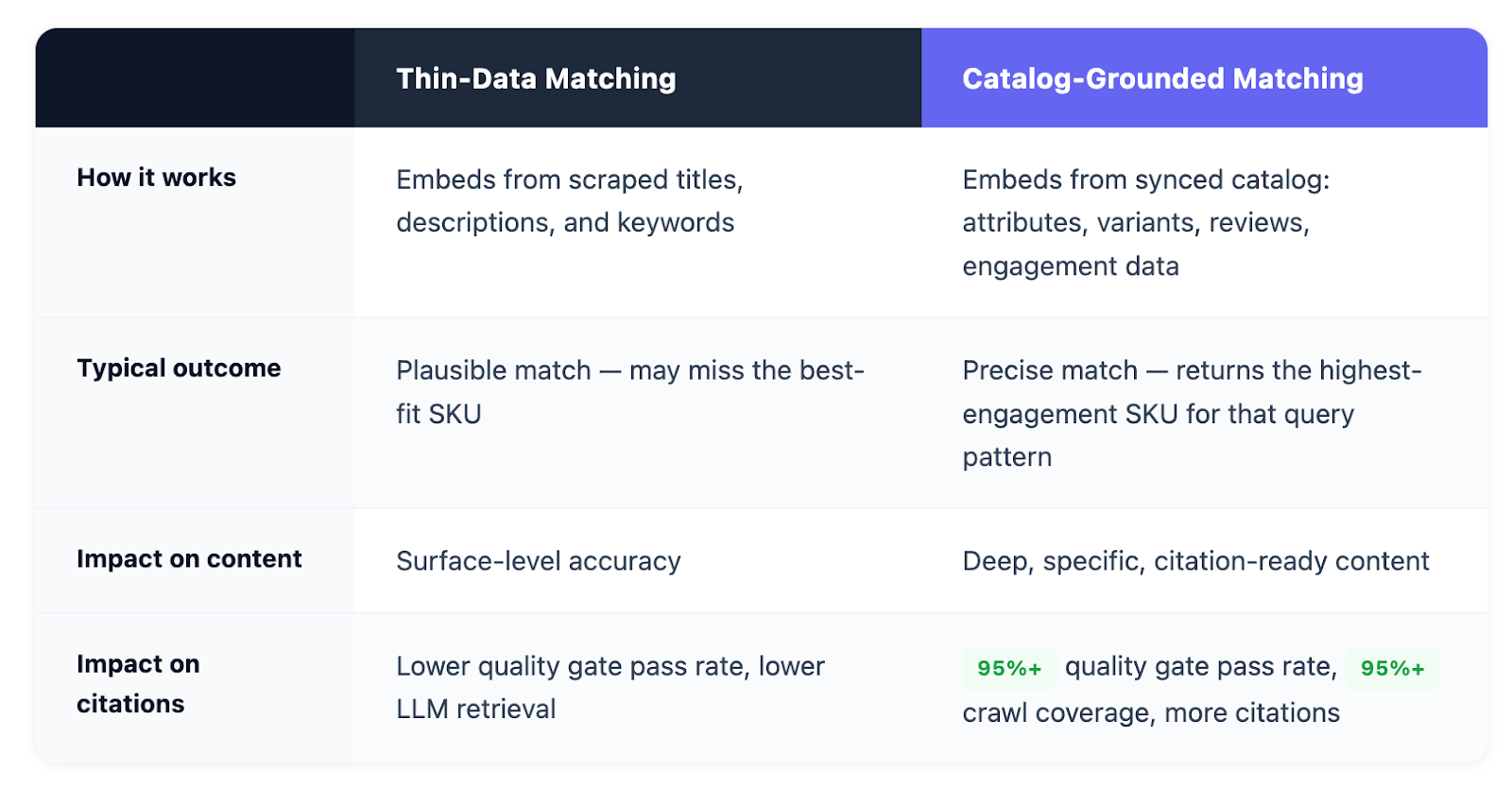
Every AI search tool uses some form of semantic matching, embeddings that translate language into mathematical representations so the system can find the closest match. The technology is the same. What differs is what gets embedded. Most tools work from thin inputs: a product title, a scraped description, a handful of keywords. The result is a plausible match, something that sounds right, but not necessarily the precise product that actually answers the query.
The alternative is to embed from the full product catalog: structured attributes, variant-level data, category hierarchies, customer reviews, and real engagement patterns. When the input is that rich, the match isn't a guess. It's grounded in what the product actually is, who it's for, and how real shoppers have responded to it.
The downstream consequences are significant. When a thin match pairs the wrong product with a high-intent prompt, the content built around it inherits that imprecision. It reads like it could be right, but it isn't specific enough to earn trust, from quality gates, from AI retrieval systems, or from the shoppers who ultimately land on it. Content that maps the wrong product to the right question doesn't get cited, because LLMs evaluate accuracy before they surface anything.
When a product catalog is synced, not scraped, but structurally integrated, every SKU can be embedded with its full context: attributes, variants, descriptions, categories, reviews, and engagement data. The result is a vector space where products cluster by what they actually are and how they actually perform, not just by how they're described in a title.
When a query comes in, the system finds the product that sits closest in that vector space, accounting for the full picture. It's semantic search, but the semantics are built from rich, structured catalog data instead of a thin scrape of a product page.
The practical difference is precision. Take a real example from our own work: a user asks "does creatine dissolve in cold water?" A thin-data match might return any generic creatine product, it sees "creatine" in the query, finds "creatine" in a title, and calls it a match. But a catalog-grounded system surfaces GNC's specific creatine products that are actually more soluble, because the embeddings account for richer product attributes and real customer reviews that mention solubility. The system catches nuances that a scraped title never could. That's not a marginal improvement. It's a categorically different level of accuracy.
The impact was measurable. When FERMÀT shifted its matching layer to embed from the full synced product catalog rather than surface-level product data, content accuracy improved dramatically. Content that hadn't been clearing internal quality gates, because it was pairing imprecise products with specific queries, started passing consistently once the matching layer was grounded in rich catalog data. FERMÀT's internal quality checks, which evaluate content accuracy before publication, saw pass rates climb from under 50% to over 95%.
The connection between matching precision and citation rates is direct. LLMs evaluate content before they cite it, and the signals they use to score relevance are unforgiving:
Content that scores high on those signals gets cited. Content that scores low gets skipped.
This is what brands on FERMÀT's platform have seen firsthand: the content that stays at the surface doesn't earn citations. The content that goes one level deeper does. As one early FERMÀT brand put it, "the content that wasn't performing wasn't wrong,it just wasn't specific enough."
The content that earns citations goes one level deeper. Retrieval-augmented generation systems, the architecture behind ChatGPT's web search and Perplexity's real-time answers, prioritize content that is grounded and specific over content that is plausible but vague.
A page that says "creatine supports muscle recovery" is plausible. A page that explains exactly which creatine formulation, at what dosage, for what training profile, with what supporting evidence, is specific. LLMs cite the second kind.
The product catalog is the foundation of that specificity. When the catalog is structured, accurate, and rich with product attributes, the content built from it reflects that quality. When the catalog is incomplete or poorly structured, the content inherits those gaps. When the feed is incomplete or poorly structured, the content inherits those gaps.
The Crawl Coverage Benchmark
One signal that the content quality approach is working at scale: FERMÀT has achieved over 95% crawl coverage on AI search content across all brands. Crawl coverage measures how much of the published content is being indexed and retrieved by AI platforms, it's a proxy for whether the content is meeting the quality and structural thresholds that LLMs require to surface it.
A number below that benchmark typically indicates content that's being skipped: too thin, too generic, or too poorly structured to clear the retrieval bar. At over 95%, the content is clearing it at a rate that reflects the precision of the underlying matching layer. The catalog-grounded approach isn't just improving content accuracy before publication, it's producing content that holds up through the full retrieval cycle.
Most brands building AI search content are starting from the wrong place. They're generating content from keyword lists, scraped descriptions, or broad category mappings. The answer is that the matching layer was never rich enough to produce content worth citing.
The brands that close the precision gap, by embedding from synced catalogs with real engagement data, mapped to real query patterns are producing content that LLMs want to surface. Not because it's optimized in the traditional sense, but because it's accurate. It answers the question correctly. It maps the right product to the right prompt. And in an environment where LLMs are actively evaluating the quality of what they retrieve, accuracy is the only optimization that matters.
"The brands winning in AI search aren't just publishing more content," says Shreyas Kumar, CTO of FERMÀT. "They're publishing content that's actually right, right product, right context, right level of depth. That precision is what separates content that gets cited from content that gets ignored."
The precision gap is real. It's measurable, and it's widening. The brands that close it now are building a content foundation that compounds. The brands that don't are generating AI slop at scale.